前回のCCFinderのネタからこっち、id:Seasons さんから頂いたコメントを読み返しつつ、プログラムの「評価基準」って何だろね?と時折ぐーぐるしてました。
…そ〜いえば、オープンソース系で評価ツールって、何かあったっけなぁ?と思いつつ、適当に ぐーぐるしていたんですが、この手のソフトは Javaが圧倒的にヒットしますねぇ。まぁ、.NET系に比べて年数も違うし、マクロやテンプレートなんていう一歩間違えるとダークサイドなものもありませんからね。
そんな中、ccccっていう冗談みたいなソフトを見つけました。
- SourceForge.net: C and C++ Code Counter
http://sourceforge.net/projects/cccc - UNIXの部屋 検索:cccc (*BSD/Linux/Solaris)
http://x68000.q-e-d.net/~68user/unix/pickup?cccc
調べてみると、Windows版も用意しているし、コード行数だけでなく、複雑度(McCabeのサイクロマチック数)も計測してくれるようです。
McCabeって何やねん?という方は、↓こちらがお奨めです。
- So-net blog:老プログラマーの備忘録:McCabeの複雑度
http://blog.so-net.ne.jp/a_Programmer/2007-07-30- マッケーブの循環的複雑度 (McCabe's cyclomatic complexity)
http://www.linkclub.or.jp/~tumibito/soft-an/metrics/mccabe.htmlその手の本を読んでいると、20〜30をオーバーした辺りが、「あんたのコード複雑すぎやねん」警戒域っぽいです。
ccccでメトリクス収集してみる
で、早速Windows版(CCCC_3.1.4_setup.exe)をダウンロードして試してみました。(対象ソースは、ひげぽんさんのMonaのkernel部分)
F:\Wacky\mona\stable\Mona\src>dir /b /s kernel | cccc - CCCC - a code counter for C and C++ =================================== A program to analyse C and C++ source code and report on some simple software metrics Version 3.1.4 Copyright Tim Littlefair, 1995, 1996, 1997, 1998, 1999, 2000 with contributions from Bill McLean, Herman Hueni, Lynn Wilson Peter Bell, Thomas Hieber and Kenneth H. Cox. The development of this program was heavily dependent on the Purdue Compiler Construction Tool Set (PCCTS) by Terence Parr, Will Cohen, Hank Dietz, Russel Quoung, Tom Moog and others. CCCC comes with ABSOLUTELY NO WARRANTY. This is free software, and you are welcome to redistribute it under certain conditions. See the file COPYING in the source code distribution for details. Parsing No language found for extension .cvsignore Processing F:\Wacky\mona\stable\Mona\src\kernel\.cvsignore - no parseable langua ge identifiedProcessing F:\Wacky\mona\stable\Mona\src\kernel\Array.h as C/C++ (c ++.ansi) Processing F:\Wacky\mona\stable\Mona\src\kernel\BitMap.cpp as C/C++ (c++.ansi) Processing F:\Wacky\mona\stable\Mona\src\kernel\BitMap.h as C/C++ (c++.ansi) No language found for extension .o ... Couldn't open Generating HTML reports Generating XML reports Primary HTML output is in .cccc/cccc.html Detailed HTML reports on modules and source are in .cccc Primary XML output is in .cccc/cccc.xml Detailed XML reports on modules are in .cccc Database dump is in .cccc/cccc.db
使い方説明にもありますが、"dir /b /s | cccc - "でOKらしいです。
実行完了すると、".cccc"フォルダが出来て、その中に解析結果のファイルが、たんまり入っています。
以下は、cccc.html(プロジェクトの概要)を開いた様子です。
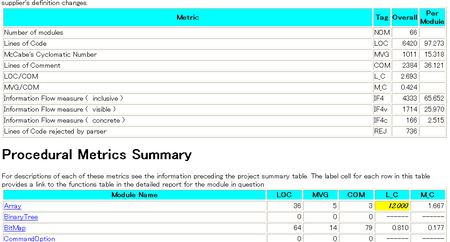
cccc1 posted by (C)wacky
メトリクスをCSVファイル化してみる
で、これはこれで「おぉ〜っ」なんですが、プロジェクト全体の複雑度合計をもらっても、あんまり役に立たないです。
欲しいのは、「複雑度が高いのは、どの関数のコード?」なんですから。
という訳で、ccccを呼び出した際に吐き出すXMLファイルを、CSVファイルに集計し直すスクリプトを、Pythonで作ってみました。
以下の感じに呼び出します。
$ dir F:\Wacky\mona\stable\Mona\src のディレクトリ 2007/08/14 21:21 <DIR> . 2007/08/14 21:21 <DIR> .. 2007/08/14 19:43 <DIR> .cccc 2007/08/13 12:27 663,552 cccc.exe 2007/08/14 19:37 4,119 cccc2csv.py 2005/02/13 17:20 <DIR> kernel 1970/01/01 09:00 <DIR> lib 2004/12/09 23:58 490 Makefile 2007/08/14 21:21 68,946 metrics.csv 1970/01/01 09:00 <DIR> servers $ python cccc2csv.py ... .cccc\VesaInfoDetail.xml .cccc\VesaScreen.xml .cccc\VirtualConsole.xml .cccc\word.xml
実行完了すると、デフォルトでは"metrics.csv"が出来ています。
Excelで開くと、以下の感じになります。
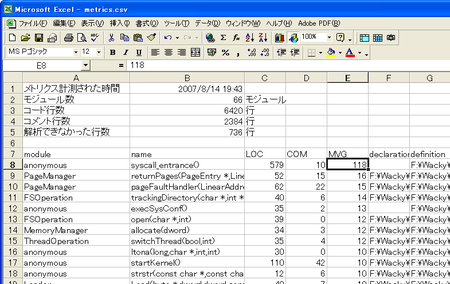
cccc2 posted by (C)wacky
各列の意味は、以下の通りです。
| module | モジュール名称 |
| name | 関数名 |
| LOC | コード行数 |
| COM | コメント行数 |
| MVG | 複雑度(20〜30を超えないようにすればOKですかね?) |
| declaration | 関数の定義(*.h) |
| definition | 関数の実装部(*.cpp) |
という訳で、作ったソースコードを以下に示します。
#!/usr/bin/env python # coding: cp932 # # usage: python cccc2csv.py """ cccc.exeコマンドを使って、メトリクス集計されたデータを、より見やすいCSVファイル化する。 CSVファイル化すれば、Excelで簡単に見れる理屈。 ccccについては、以下を参照。 - SourceForge.net: C and C++ Code Counter http://sourceforge.net/projects/cccc - UNIXの部屋 検索:cccc (*BSD/Linux/Solaris) http://x68000.q-e-d.net/~68user/unix/pickup?cccc """ import sys try: import elementtree.ElementTree as ET # Python 2.4 except ImportError: import xml.etree.ElementTree as ET # Python 2.5 import fnmatch import os import os.path import time, datetime # CSV書き込みするファイルオブジェクト(Noneだと、標準出力) g_f = None # CSV書き込みする際のヘッダタイトル g_o_def = ['module', 'name', 'LOC', 'COM', 'MVG', 'declaration', 'definition'] def usage(): print """ <<<%s の使用方法>>> cccc.exeを呼び出した後、'.cccc'フォルダが出来る。 メトリクス集計された'*.xml'を読み出し、CSVファイル化する。 --l ['.cccc'フォルダの場所を指定する('.cccc'がデフォルト)] --s [結果を保存するCSVファイル名] : 指定しないと標準出力する --help or /? : 使い方の説明 """ % (sys.argv[0]) def prt(msg): """g_fに対して、文字列を書き込む""" if g_f == None: print msg else: print >>g_f, msg def prt_head(keys): """g_fに対して、ヘッダ行相当を書き込む""" global g_f s = "" for k in keys: s = s + "," + ('"%s"' % k) if g_f == None: print s[1:] else: print >>g_f, s[1:] def prt_line(o, keys): """g_fに対して、中身相当を書き込む""" global g_f s = "" for k in keys: s = s + "," + ('"%s"' % o.get(k, '')) if g_f == None: print s[1:] else: print >>g_f, s[1:] def project_summary(fpath): """プロジェクトの概要を書き出す -fpath cccc.xmlを指定しましょう """ o = ET.parse(fpath) s = o.findtext("timestamp").strip() t1 = time.strptime(s) t2 = datetime.datetime(*t1[:6]) prt('メトリクス計測された時間,%s' % t2.isoformat(' ')) NOM = o.find("project_summary/number_of_modules") prt("モジュール数," + NOM.attrib['value'] + ",モジュール") LOC = o.find("project_summary/lines_of_code") prt("コード行数," + LOC.attrib['value'] + ",行") COM = o.find("project_summary/lines_of_comment") prt("コメント行数," + COM.attrib['value'] + ",行") REJ = o.find("project_summary/rejected_lines_of_code") prt("解析できなかった行数," + REJ.attrib['value'] + ",行") def xml_parse(fpath): """指定モジュール(fname)の各メソッドのメトリクスを書き出す -fpath *.xmlを指定しましょう(cccc.xmlは不要) """ tree = ET.parse(fpath) mod_name = os.path.splitext(os.path.basename(fpath))[0] funcS = tree.findall("*/member_function") for func in funcS: o = {} o['module'] = mod_name for e in func: #print e.tag if e.tag == 'name': o['name'] = e.text elif e.tag == 'lines_of_code': o['LOC'] = e.attrib['value'] elif e.tag == 'McCabes_cyclomatic_complexity': o['MVG'] = e.attrib['value'] elif e.tag == 'lines_of_comment': o['COM'] = e.attrib['value'] elif e.tag == 'extent': s = e.find('description').text e2 = e.find('source_reference') o[s] = '%s:%s' % (e2.attrib['file'], e2.attrib['line']) #print o prt_line(o, g_o_def) def main(): load_dir = ".cccc" save_path = "metrics.csv" if len(sys.argv) > 1: # 引数解析 i = 1 while i < len(sys.argv): s = sys.argv[i] print i, "=", s i = i + 1 if s == "--l": load_dir = sys.argv[i] elif s == "--s": save_path = sys.argv[i] elif (s == "--help") or (s == "/?"): usage() return else: continue i = i + 1 if len(save_path) != 0: global g_f g_f = file(save_path, 'w') try: # プロジェクトの概要(cccc.xml)を書き出す project_summary(load_dir + "\\cccc.xml") prt("") # 全てのモジュールの詳細(*.xml)を書き出す prt_head(g_o_def) for root, dirs, files in os.walk(load_dir): for fname in files: if fnmatch.fnmatch(fname, "*.xml"): if fname != "cccc.xml": fpath = os.path.join(root, fname) print fpath xml_parse(fpath) finally: if g_f != None: g_f.close() if __name__ == "__main__": ret = main()
最後に
集計プログラムを作りながら、
- 「日々、コード行数を計測してグラフ化したら、どうなるんだろうなぁ」
- 「コード行数に対して、コメント行数の率が減っていくとしたら、どんな状況だろう?」
- 「複雑度は、コードレビュー時の、集中してみる箇所の目安にならんかしらん?」
と、にやにや考えていたのは、秘密だよ。(を?
後、ElementTreeモジュールは、便利ですねぇ。
最初、Pythonクックブックを読みながら、saxモジュールとdomモジュールの どっち使おう?と考え込んでいたんですが、いつの間にか、こっちを使ってました。